WordPress doesn’t search inside PDF files. Not by default, not ever. You can upload hundreds of documents and your site’s search bar will ignore every word inside all of them.
This guide covers everything — why it happens, how to fix it, how to handle scanned documents and private files, how to read your index activity, and what to do when things go wrong. If you manage PDFs on a WordPress site, this is the only reference you need.
Table of Contents
- Why WordPress Doesn’t Search Inside PDFs
- The Two Types of PDFs on Most Sites
- Setting Up PDF Search — Free
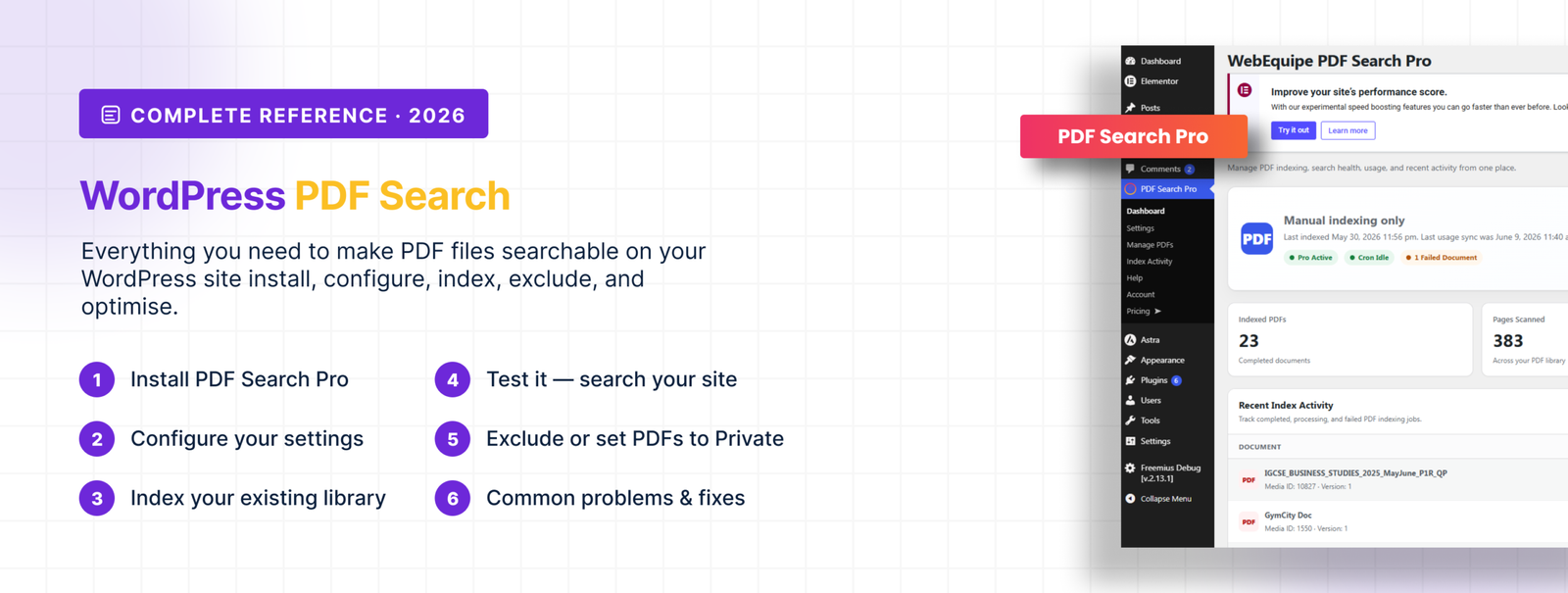
- Dashboard Overview
- Handling Scanned PDFs with OCR
- Keeping PDFs Private or Out of Search
- Managing Your PDF Library
- Index Activity
- Search Results — What Visitors See
- Common Problems and Fixes
- Free vs Pro — When to Upgrade
- FAQ
Why WordPress Doesn’t Search Inside PDFs
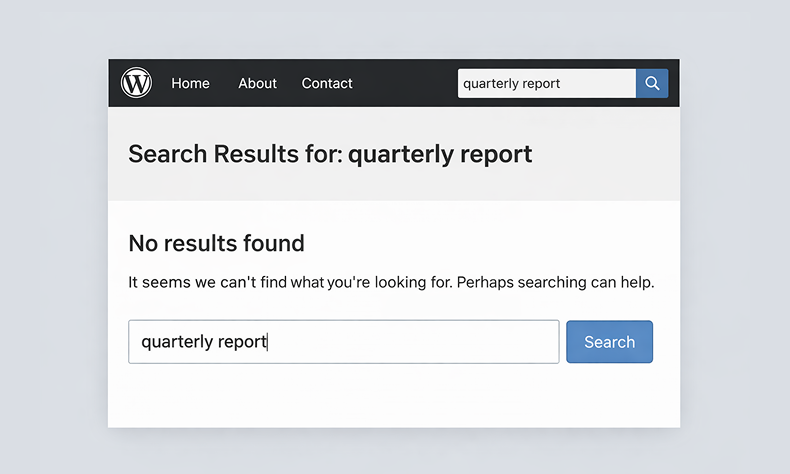
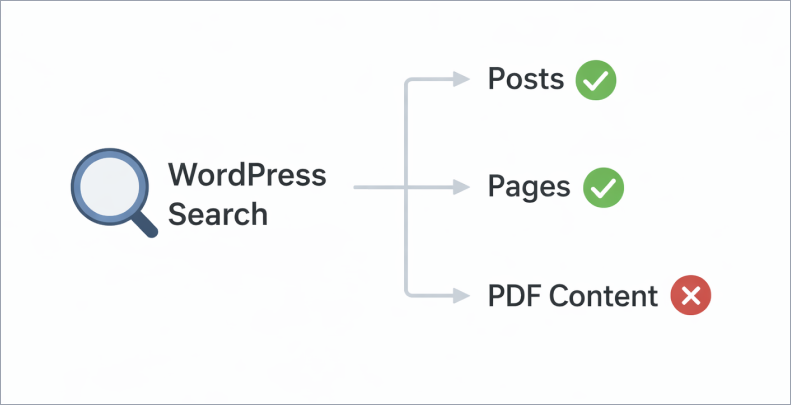
WordPress search queries a single database table that stores post and page content. When you upload a PDF, WordPress records the filename, file size, and URL. That’s the extent of it. The text inside the file is never read, never stored, never searchable.
This isn’t something that gets fixed by tweaking settings or installing a general search plugin. You need a plugin specifically built to extract text from PDF files and store it in a searchable index. That’s what WebEquipe PDF Search does.
The Two Types of PDFs on Most Sites
Before setting anything up, it helps to know what you’re working with.
Text-based PDFs are created digitally — exported from Word, Google Docs, InDesign, or any document software. The text exists as real, selectable characters inside the file. Open one in your browser and you can highlight words, copy sentences, search the document. These are straightforward to index.
Scanned PDFs are photographs of physical pages saved as PDF files. The content is an image, not text. You can’t highlight anything inside them. A standard PDF search plugin marks these as Error because there’s nothing to extract.
Most document-heavy sites have both. Old archived reports, meeting minutes, forms designed for print — these tend to be scanned. Anything created or exported recently is usually text-based.
Knowing which type you’re dealing with determines which setup path you take.
Setting Up PDF Search — Free
The free version of WebEquipe PDF Search handles text-based PDFs. Install it, index your library, and your documents become searchable in minutes.
🟥 Install and activate
Go to Plugins → Add New, search for WebEquipe PDF Search, install and activate. A PDF Search menu appears in your WordPress admin sidebar.
🟥 Configure settings
Go to PDF Search → Settings and confirm two things are on:
- Enable PDF Indexing — new uploads get indexed automatically when this is on. Every PDF you add to your Media Library gets processed without any extra steps.
- Enable Search Integration — PDFs appear in your site’s standard search results alongside posts and pages.
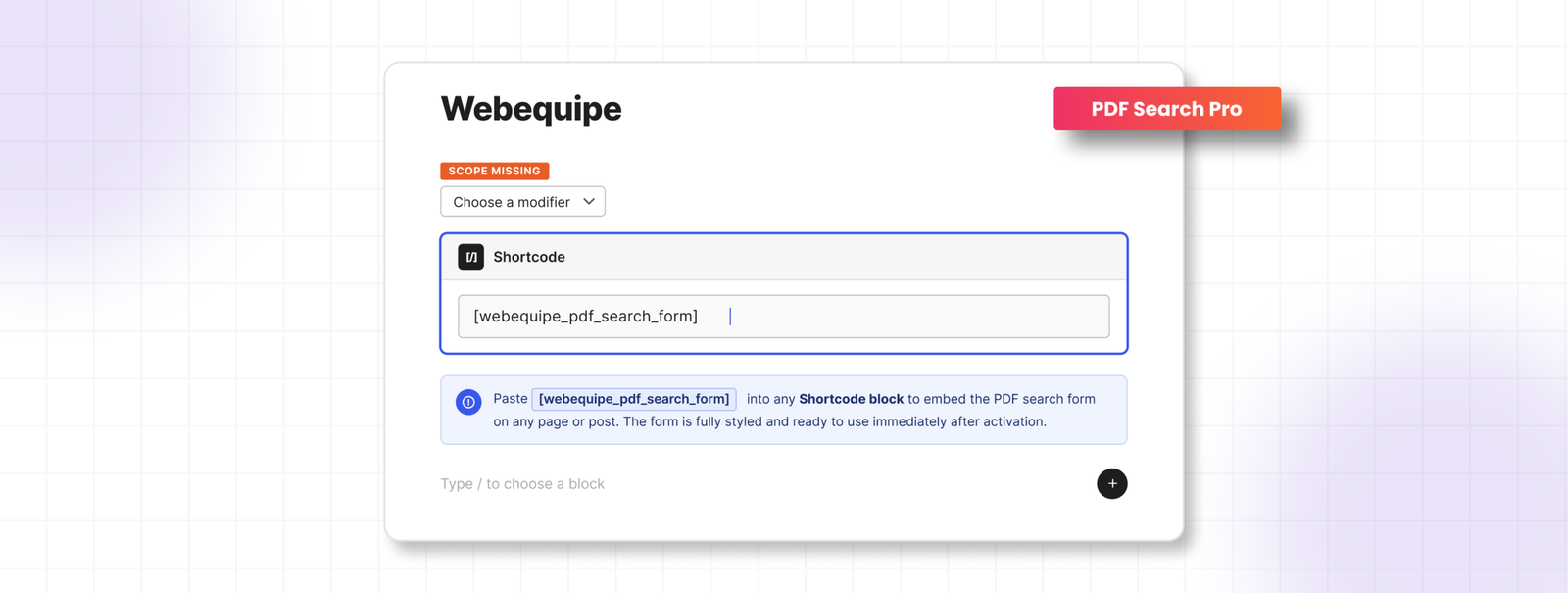
If you want PDFs in a separate search form rather than mixed with posts and pages, you can leave Search Integration off and use the shortcode instead.
🟥 How auto-indexing works
With Enable PDF Indexing on, the moment you upload a PDF to your Media Library the plugin queues it for processing. For small files this happens immediately. For larger files — or if Background Processing is enabled — it queues and runs in the background so it doesn’t block the upload.
You’ll see the PDF status change from Not Indexed to Processing to Indexed in your Media Library column as it works through.
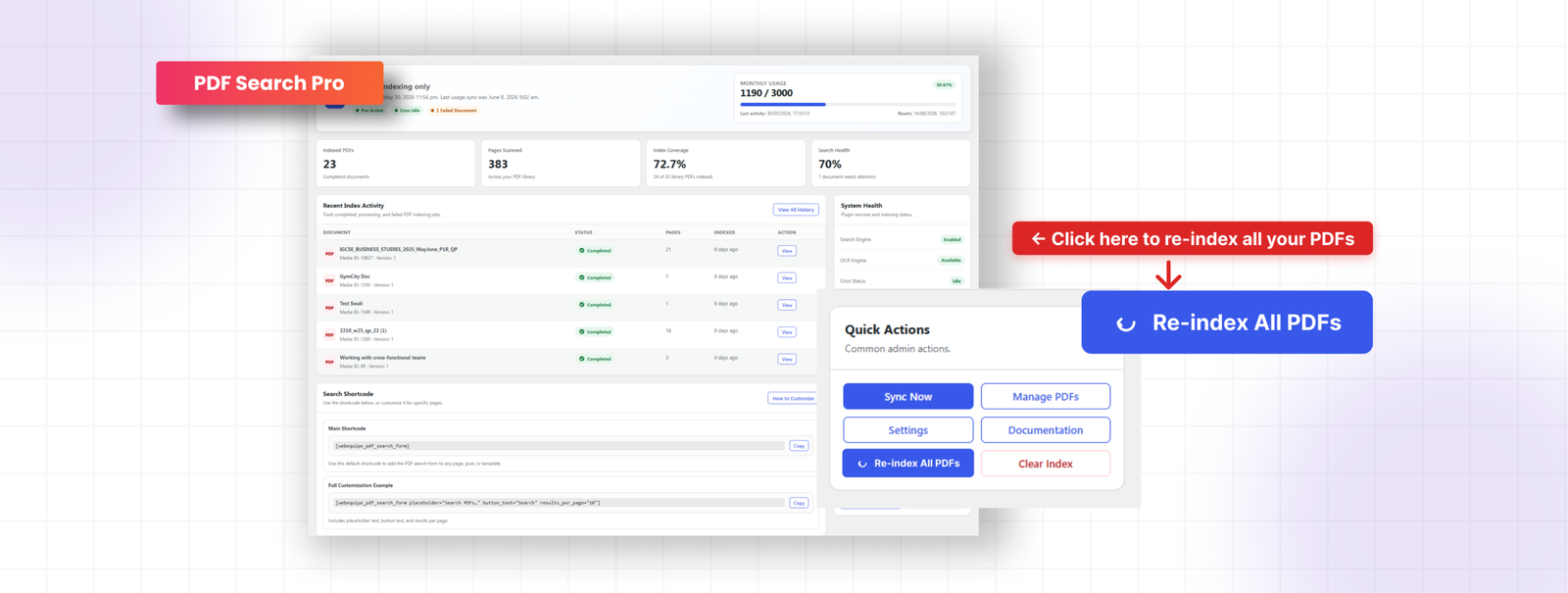
🟥 Index your existing library
The plugin doesn’t automatically pick up PDFs already in your Media Library before it was installed. Go to PDF Search → Dashboard and click Re-index All PDFs. This processes everything in your library and builds the index from scratch. Large libraries run in batches in the background.
This searches only your indexed PDFs, completely separate from your site’s main search. Useful for resource centres, help sections, or document portals.
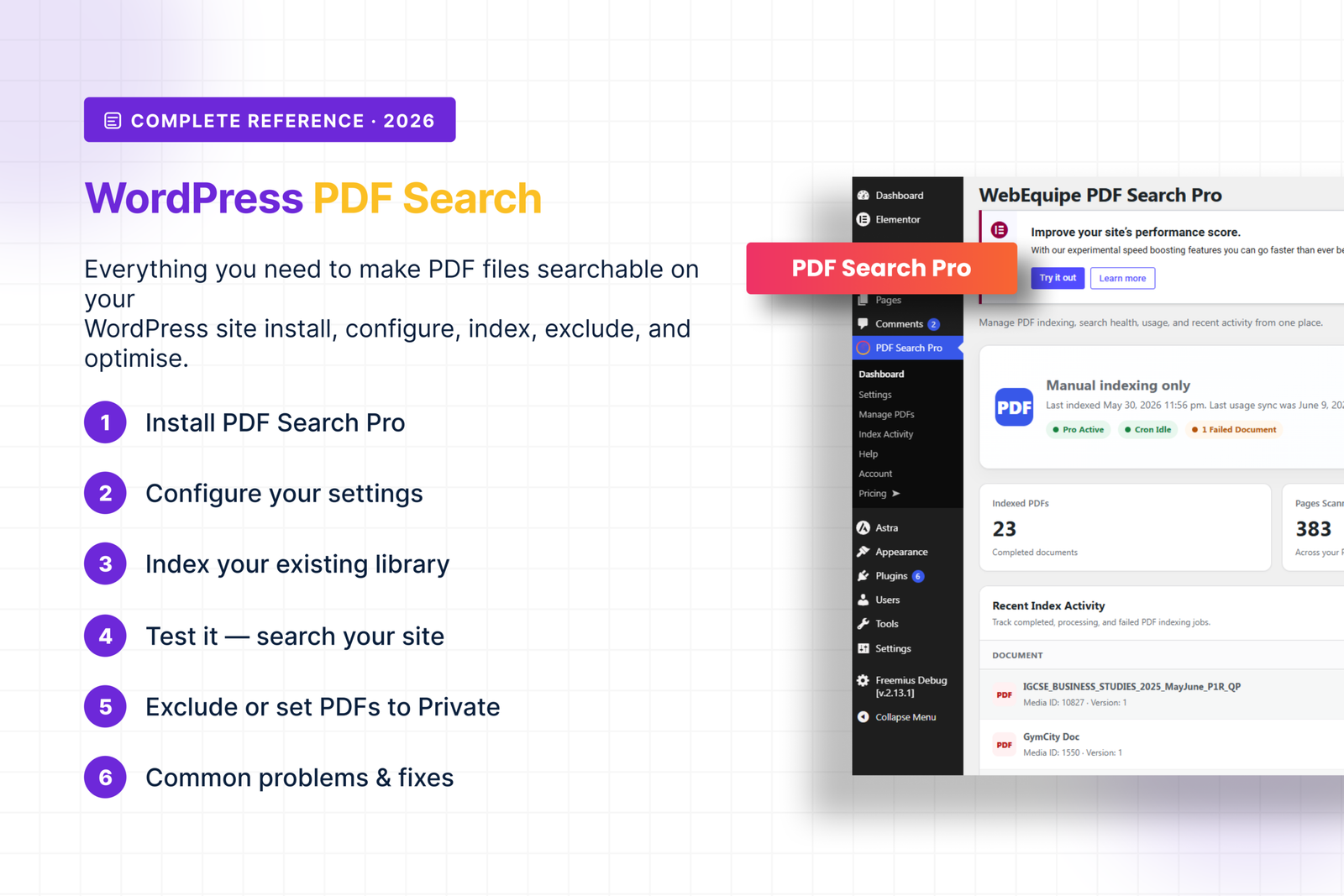
Dashboard Overview
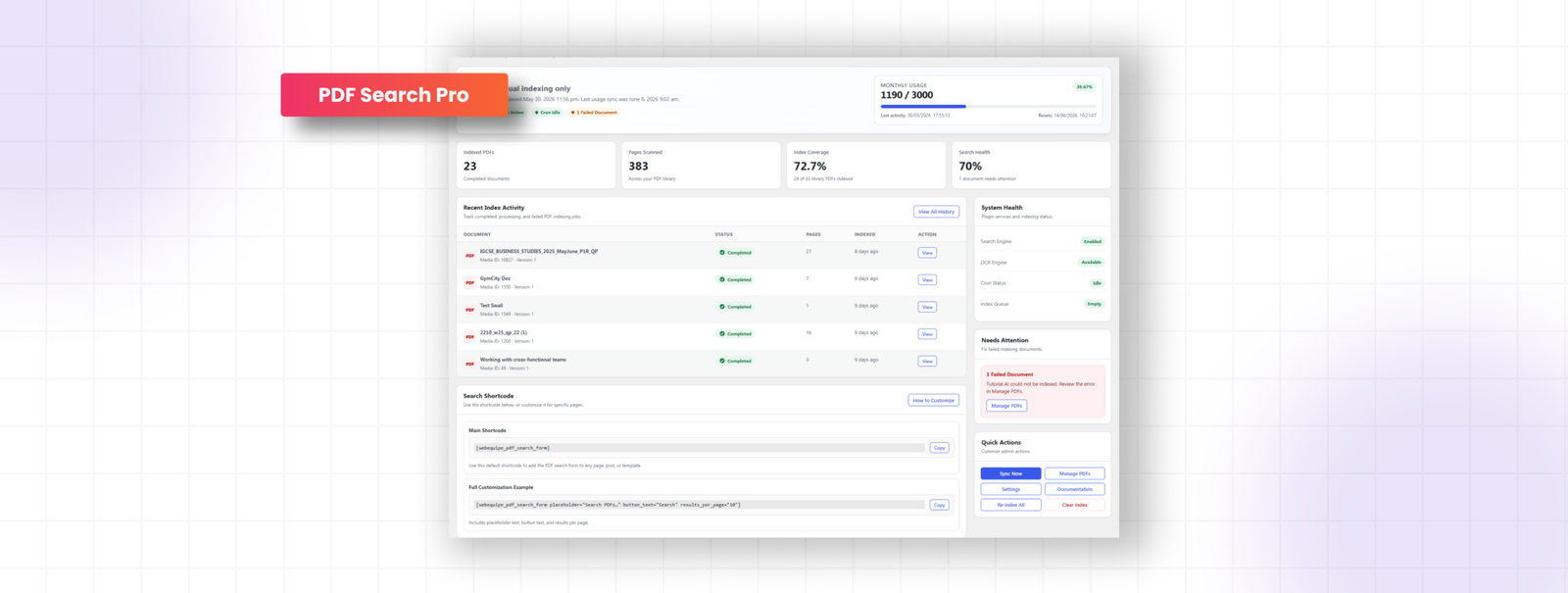
PDF Search → Dashboard is your home screen. Here’s what everything means.
🟥 Metric cards at the top
Metric cards at the top show indexed PDF count, total pages scanned, index coverage percentage, and search health status. Coverage tells you what proportion of your library is actually indexed — if it’s significantly below 100%, there are PDFs that need attention.
🟥 Status headline
Status headline gives you an at-a-glance reading of your setup — whether indexing is healthy, whether there are failed documents, and whether your cron is running correctly. If something needs attention it flags it here with a link directly to the problem.
🟥 Recent index activity
Recent index activity shows the latest indexing runs — which files were processed, when, and whether they succeeded. This is a preview of the full Index Activity log.
🟥 System health sidebar
System health sidebar shows your PHP version, memory limit, processing timeout setting, and cron status. If background processing is running slowly or failing silently, the cron indicator here is usually the first place that shows it.
🟥 Quick actions
Re-index All PDFs, go to Settings, go to Manage PDFs — are all accessible from the Dashboard without navigating away.
Handling Scanned PDFs with OCR
Scanned PDFs require OCR to be indexed. The plugin uses Google Vision — available on Starter, Pro, and Agency plans.
🟥 Set up OCR
Once your licence is active, go to PDF Search → Settings and set the Indexing Method to Native + OCR Fallback. Text-based PDFs get processed locally. Scanned files get routed to Google Vision automatically. You don’t decide per file.
🟥 Fix existing scanned PDFs
Go to PDF Search → Manage PDFs, filter by Error, select all the failed files, and run the bulk action Index OCR. Those files get sent to Google Vision and come back indexed.
🟥 OCR credits
Each plan includes a monthly page allowance — Starter gets 1,000 pages, Pro gets 3,000, Agency gets 10,000. Usage is visible in PDF Search → Dashboard.
Full OCR walkthrough: How to Make Scanned PDFs Searchable in WordPress →
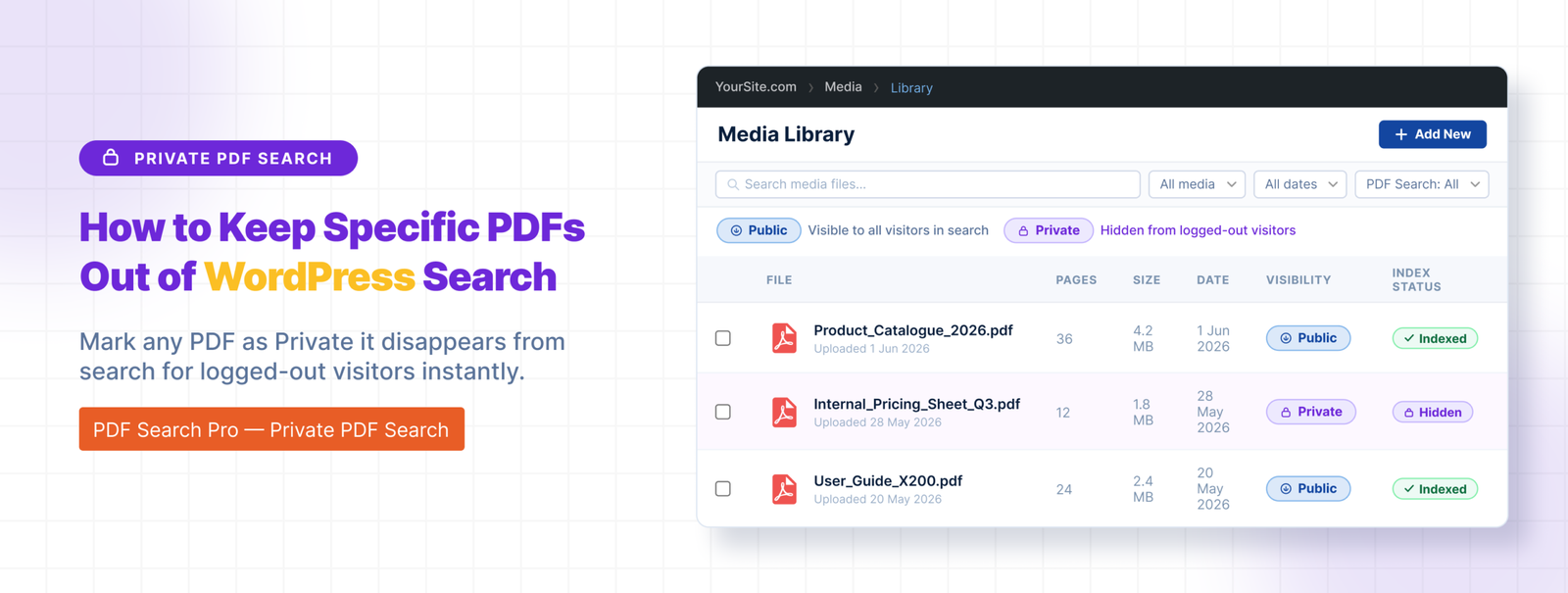
Keeping PDFs Private or Out of Search
Not every PDF on a site should be publicly searchable. There are two ways to handle this.
Exclude removes a PDF from search entirely. Nobody finds it — logged in or not. The file stays in your Media Library but is never indexed. Use this for drafts, outdated versions, and internal files that should never appear in any search results.
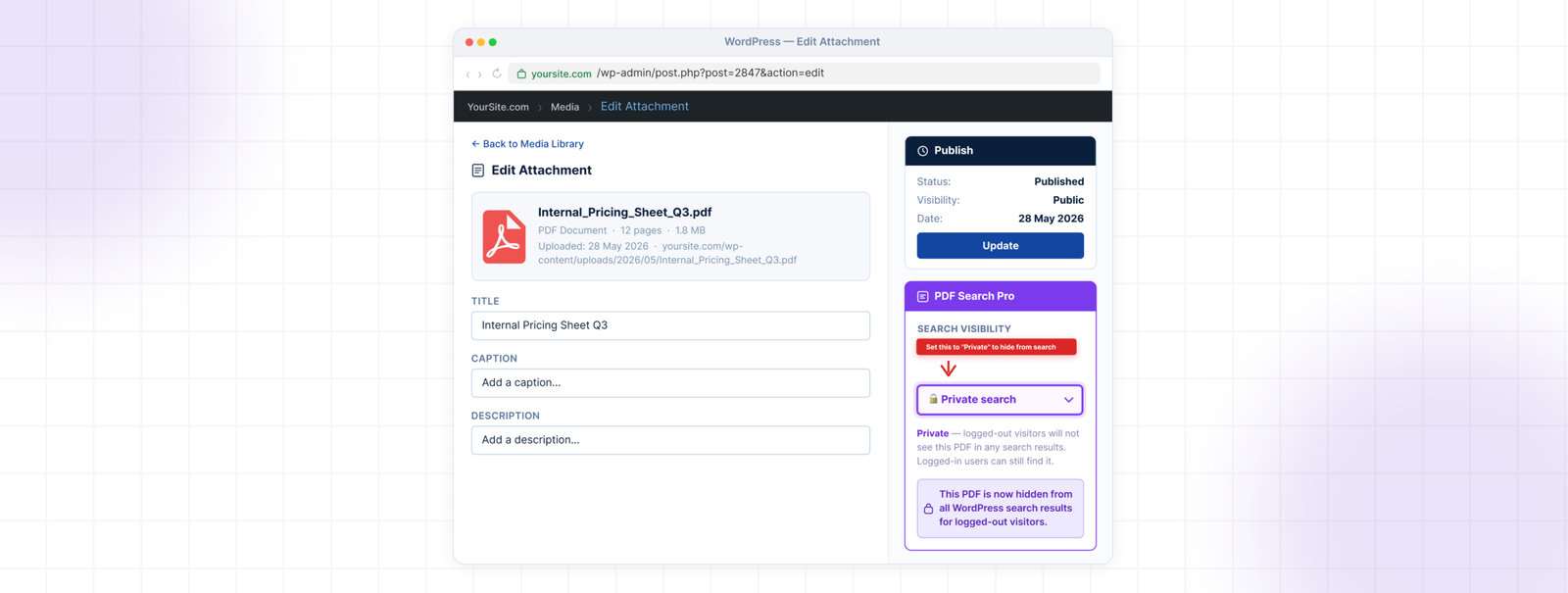
Private PDF Search keeps the PDF indexed but hides it from logged-out visitors. Logged-in users can still find it. Use this for member resources, staff documents, and restricted content that registered users need access to.
Exclude is available in the free plugin. Private PDF Search requires Pro or Agency.
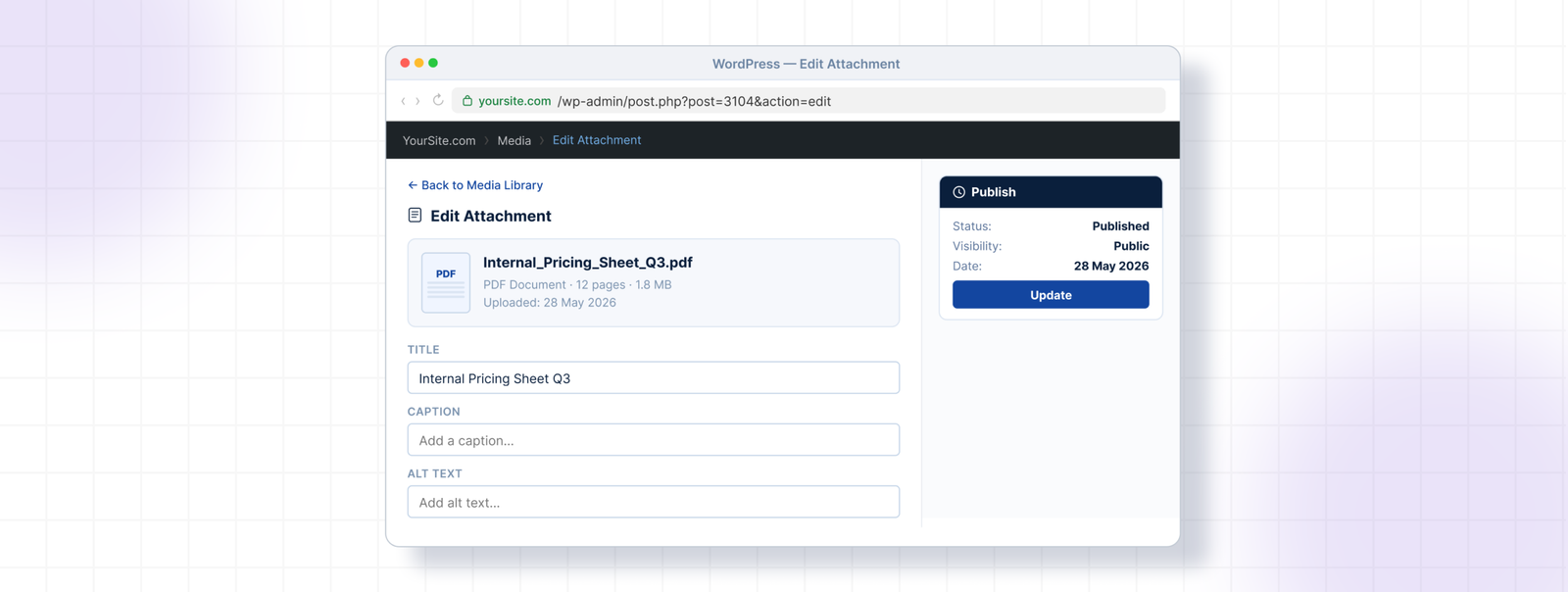
To exclude a PDF: open it in Media → Library, find the WebEquipe PDF Search panel, click Exclude.
To set a PDF to private: open it in Media → Library, set Search Visibility to Private, save.
Full guide: How to Keep Specific PDFs Out of WordPress Search →
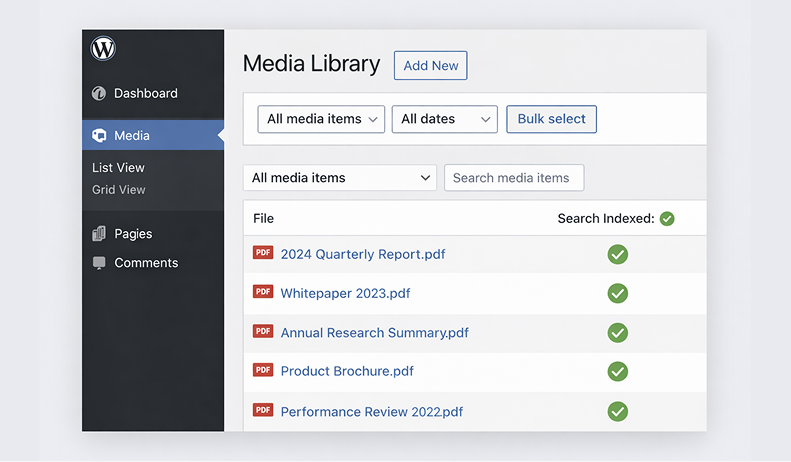
Managing Your PDF Library
PDF Search → Manage PDFs gives you a full picture of everything in your library with filtering, bulk actions, and per-file controls.
Every PDF has a status badge:
- Indexed — in search, working correctly
- Not Indexed — in your library but not yet processed
- Processing — currently being indexed
- Scheduled — queued for background processing
- Error — indexing failed, usually scanned or corrupted
- Excluded — deliberately removed from search
🟥 Background processing
For large PDFs or libraries with many files, Background Processing moves indexing into a WP-Cron queue so it runs independently of the browser. Without it, a very large PDF can hit PHP execution limits mid-process and fail.
Enable it in PDF Search → Settings → Advanced → Enable Background Processing. Once on, PDFs above the page index threshold are automatically queued as Scheduled and processed in batches. You can leave the admin and come back — the queue runs on its own.
The batch size and page threshold are configurable in the same settings screen if you need to tune performance for your hosting environment.
🟥 Bulk actions
From Manage PDFs you can select multiple files and run: Index, Index OCR, Unindex, Exclude, Include, Make Public, Make Private. Useful for processing a filtered subset — for example, selecting all Error PDFs and bulk running Index OCR.
Index Activity
PDF Search → Index Activity is the full processing log — every indexing run recorded with timestamp, file name, status, page count, processing method, and duration.
🟥 Reading the log
Each row represents one indexing run for one file. The columns tell you:
- File — which PDF was processed
- Status — Completed, Processing, Failed, or Cancelled
- Method — Native, OCR, or Partial (mixed PDF)
- Pages — how many pages were indexed in that run
- Time — when the run started and how long it took
If a run shows Failed, clicking the detail icon opens the full error message — exactly what went wrong and why. This is the fastest way to diagnose a stubborn file.
🟥 Statuses explained
Completed — processed successfully, content is indexed and searchable.
Processing — currently running. If a file stays in Processing for an unusually long time, it may have stalled — the Dashboard status indicator will flag this.
Failed — indexing did not complete. The error detail explains why — scanned file, corrupted PDF, timeout, file too large, password protected.
Cancelled — a run was interrupted, either manually or because a newer run was triggered for the same file.
🟥 Export log
The full activity log can be exported as a CSV from the top of the Index Activity page. Useful for auditing a large library, sharing with support, or keeping records of when specific documents were indexed.
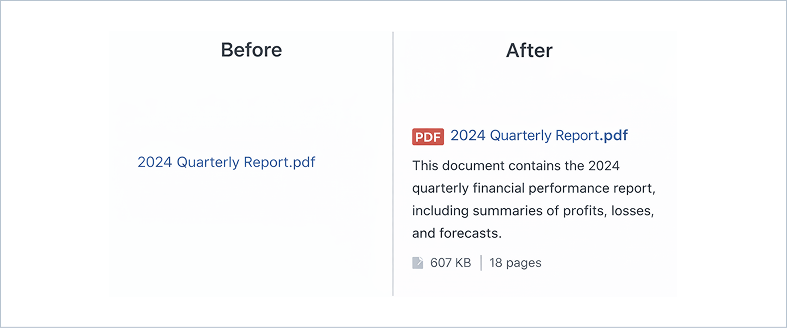
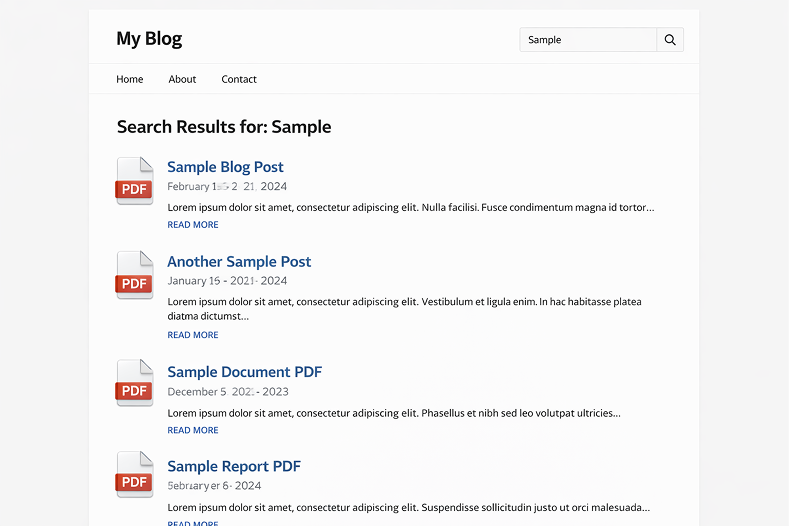
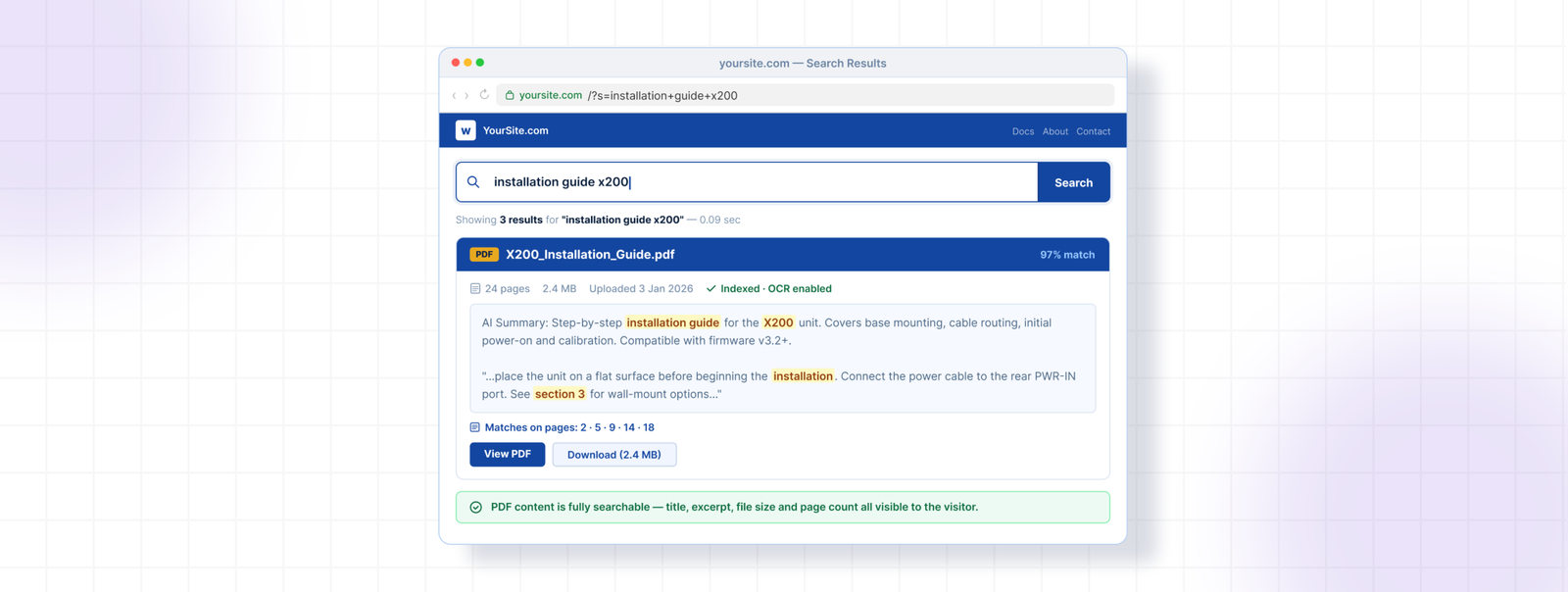
Search Results — What Visitors See
When a PDF appears in search results, visitors see the PDF title, a short excerpt from the best-matching page inside the document, file size, page count, and a direct link to open or download the file.
You can control which elements appear in PDF Search → Settings → Search Display Options. Icon, file size, page count, author, date, and excerpt can each be toggled independently.
Filenames become the displayed title in results. annual-report-2025.pdf is a lot more useful in search results than doc-v3-FINAL-revised.pdf — worth cleaning up filenames before indexing if yours are messy.
Common Problems and Fixes
PDFs not showing in search after indexing
Check that Enable Search Integration is on in PDF Search → Settings. Confirm the specific PDF isn’t Excluded.
Indexing keeps timing out
Enable Background Processing in PDF Search → Settings → Advanced. Large files need more time than a standard browser request allows.
PDFs show as Error
Almost always means the file is scanned. Filter by Error in Manage PDFs, select the files, run Index OCR. Requires a paid plan.
PDF appears in results but shows no excerpt
Text extraction returned very little content. Open the file and try to select text — if you can’t, it’s scanned.
Status stuck on Processing
The indexing job may have stalled. Go to Dashboard and check the cron status indicator. If cron is showing as disabled or broken, that’s the root cause.
Private PDFs showing in public search after licence expires
Private visibility is enforced by an active licence. Renewing restores the restriction immediately.
Free vs Pro — When to Upgrade
The free plugin covers text-based PDFs, auto-indexing, WordPress search integration, the shortcode form, Media Library management, and the full Index Activity log. For a lot of sites that’s everything they need.
Upgrade when:
- You have scanned PDFs showing as Error — OCR is the only fix, it’s not in the free plugin
- You need PDFs restricted to logged-in users — Private PDF Search requires Pro or Agency
- You’re managing multiple client sites — Agency plan covers unlimited sites with white-label mode
Frequently Asked Questions
Does WordPress search inside PDFs by default?
No. WordPress only searches post and page content. PDF files are stored as attachments — WordPress reads the filename but never the text inside. A dedicated plugin is required.
Will PDF search slow down my site?
No. Indexing runs in the background. Search queries run against the stored index, not the original files. No impact on page load times for visitors.
How many PDFs can it handle?
No hard limit. Sites with several hundred PDFs run fine. Large libraries index in batches so nothing times out.
What happens to my indexed content if I uninstall the plugin?
By default nothing is deleted — your WordPress database keeps the index tables. If you want a full clean removal, enable Delete Data on Uninstall in PDF Search → Settings → Advanced before deactivating. This removes all plugin tables, options, and post meta on uninstall.
Does it work on WordPress Multisite?
Yes. Each site in a network has its own separate index, settings, and Index Activity log.
What PDF types are supported?
Text-based and mixed PDFs work with the free plugin. Scanned PDFs require OCR (paid plans). Password-protected and corrupted PDFs can’t be indexed by any method.
Does it work with my theme?
Yes. It hooks into WordPress’s native search, so it works with any theme using standard search. The shortcode form is theme-independent.
Where to Go From Here
For specific situations, these guides go deeper: How to Make Scanned PDFs Searchable in WordPress →
How to Keep Specific PDFs Out of WordPress Search →